The test case - an epistemological deconstruction
(This article was first published in Dutch in TestNet Nieuws 18. The article below is a translation with minor changes. Many thanks to Joris Meerts and Ruud Cox for reviewing the original version.)
Testing as an information problem
Testing is an information problem. We are in search of certain information, of an answer to the question: does this application fulfill the relevant explicit and implicit expectations? The exact way in which we can answer this question, however, is not immediately clear. First we will need to decide which questions to ask, how to ask them and how to evaluate the responses. Hence, testing is an information problem.
For the traditional test methodologies (ISTQB and TMap being the most well-known) the test case is a large part of the solution. So let’s take this solution apart epistemologically and see what it is we have in front of us. If the traditional test case is our solution, what information does a test case contain? What changes occur after executing it? And also, where is the understanding in all of this that’s happening?
In this article, I will first describe how a typical test case is created and how it is used. Then we shall take a look at which kinds of information a test case contains. Finally, we will analyze where the understanding of what happens during testing, is present and where it is not.
Creation and usage of the test case
To begin with let’s find out what the traditional test methodologies have to say about creating and using test cases. Because of the philosophical nature of this article, I will only look at what these methodologies describe and ignore possible pragmatic deviations.
Test basis
A test case is created starting from the test basis. In the test basis the expectations with regards to the application are documented. Most likely not all (but close to all) explicit expectations are present. And note that some of these explicit expectations have only become so during the documentation process.
Besides the explicit expectations the test basis also contains a number of implicit expectations: expectations of which you can deduce the existence based on the explicit expectations present in the test basis. As a consequence the implicit expectations in the test basis will deviate from the ‘actual’ implicit expectations, for they are based on a different set of explicit expectations. To summarize, the test basis is not a copy, but a model of the expectations of the application.
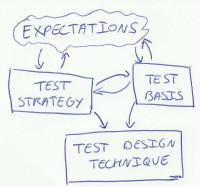
Test design technique
To create a test case one uses the test design techniques selected in the test strategy. Like the test basis, the test strategy is a transformation, a model of the explicit and implicit expectations of the application. While this is a fairly straightforward transformation in the case of the test basis (documenting expectations), it’s more complex for the test strategy. Besides expectations about the behaviour of the application, the test strategy also takes risks into account.
The combination of these two models (test basis and test strategy) by means of test design techniques results in the third model: the collection of test cases. Obviously the same applies here as with the test basis: there will not be a one-to-one relation between the test cases and the actual expectations about the application. Even more, there won’t be a one-to-one relation between the expectations documented by the test basis and the expectations documented by the test cases. Some information will be lost, some will be gained. It would be interesting to explore how all these elements (actual expectations, test basis, test strategy and set of test cases) influence each other, but unfortunately I have to leave that out of scope for this article.
Test coverage matrix
One test design technique - and I hope we’re using more than one - results in multiple test cases. Most of the time we group these test cases into for instance a test script to make test execution easier. This makes it difficult to keep track to which part (or parts) of the test basis each test case relates. The solution to this is creating a coverage matrix (aka traceability matrix): a table that documents these relations.
Test case
A test case consists of two parts: on the one hand input (test data and steps to be executed) and preconditions, on the other expected output and postconditions. More precise would be to say “expected input and preconditions”. Setting aside the question if the executing tester correctly identifies the preconditions and correctly enters the input, there is the fact that it’s no more than an expectation of ours that it’s possible to enter the specific input of the test case under the preconditions described in the test case. Until we actually try to execute the test case and see that it can be done, it is no more than that, an expectation. The same applies to the processing of the input by the application. Hence the wavy lines in the illustration.
A test case is our expectation based on the best knowledge we have when creating the test case, but that knowledge has not been tested yet. We don’t truly know anything about the application we are planning to test, until we actually test it.
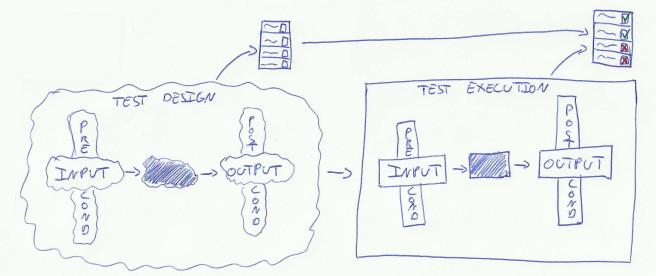
Test result
When we execute the test case, we check the preconditions, enter the input and compare the actual output with the expected output and postconditions. Based on that we decide: ‘pass’ or ‘fail’. This moment is the first time the expectations that lead to a to-be-tested application come into direct contact with the expectations that lead to a set of test cases. The result is documented in these test cases as a series of green checks and red crosses, a series of passes and fails.
Types of information in a test case
Now we have described what a test case is (a possible solution to an information problem), it’s time to look at what information is present in a test case. We can distinguish the following four types (indicated by black numbers in the illustration): 1. How the application is supposed to work; 2. How the application actually behaves; 3. Why this test case was created; 4. What has been tested. Let’s go over these one by one.
How the application is supposed to work
The information on how the application is supposed to work is present in the test case as such: the input, the expected output, the preconditions, the postconditions. As said earlier it’s important to realize that when we create the test case, we don’t know yet how the application actually behaves. We work based on expectations, also when determining the input and the preconditions. Of some expectations we are quite certain, of others less so.
This results in an interesting tension within the expectations about how the application is supposed to work: at what moment are you certain enough of a particular expectation to accept it as input and/or precondition of a test case? Another question is what information is lost when transforming the test basis by means of a test design technique to a number of test cases. We lose the implicit expectations present in the test basis in exchange for the implicit expectations present in the test cases.
This exactly is both the strength and the weakness of test design techniques: they allow us to hone in on certain specific expectations; that there is also a loss in information we just have to accept. Another thing we lose in this transformation is the structure of the test basis, the relations between its parts. Often we try to compensate this loss with a coverage matrix: how does the structure of the test basis relate to the structure of the test cases?
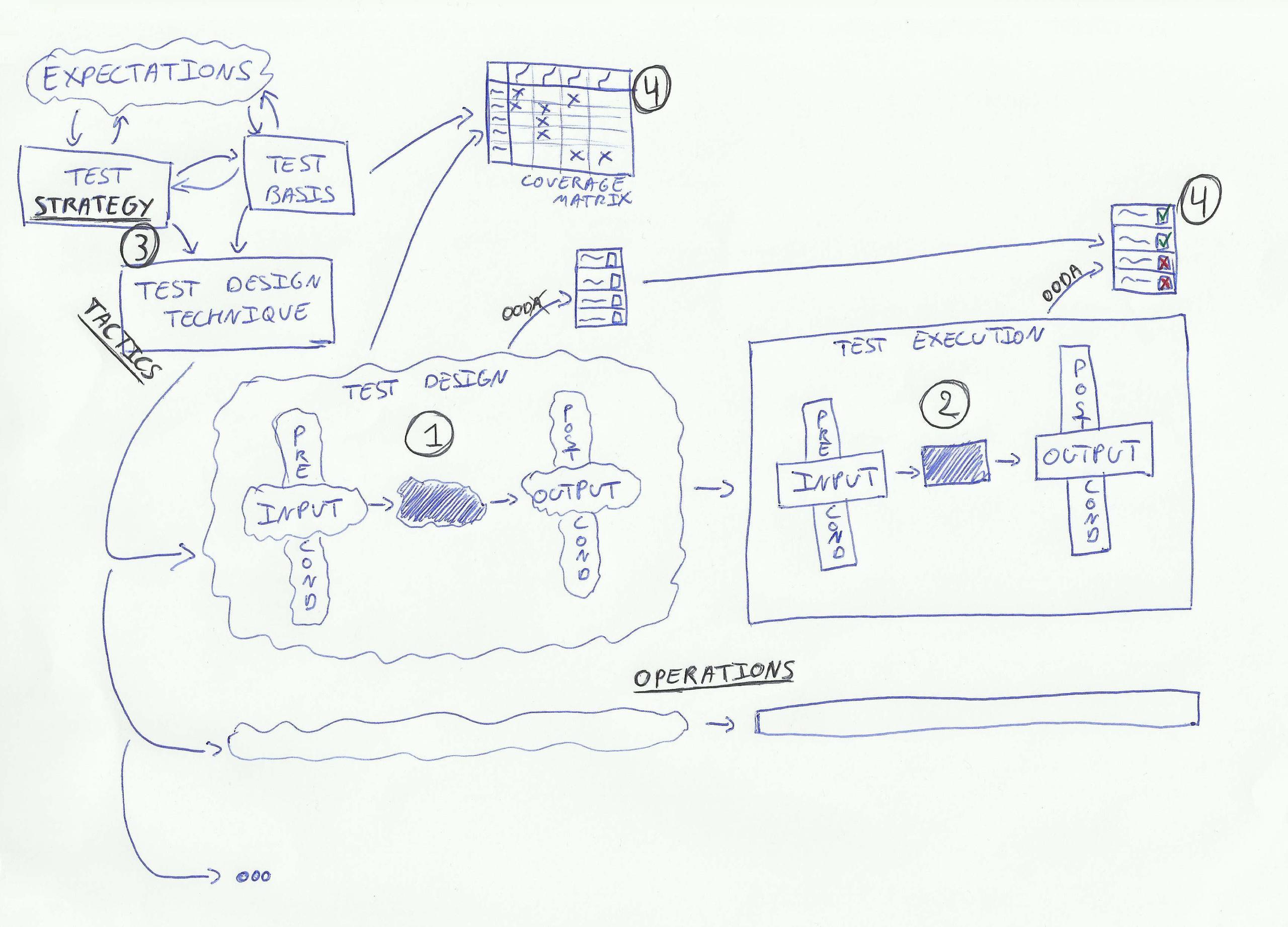
How the application actually behaves
During test execution we begin to discover how the application actually behaves. The expectations are tested against the application. One way to think about what happens is by means of John Boyd’s OODA-loop: Observe - Orient - Decide - Act. We execute the test case and go through each of the four phases: we see the output (Observe), we interpret our observations (Orient), on which we base our evaluation (Decide) and finally we do something (Act). (see illustration)
For a test case the evaluation is all about the question: Is there a problem here? Does the output conform to the expected output or not? Since the test case describes the expected output, it also is the oracle, the mechanism based on which we decide if there is a problem or not. The test case describes what you should expect to see as output; if you don’t see it, there’s a problem.
The thought processes of the tester during test execution - how we observe, how we orient, which decision we take - are thus for a large part determined in advance by the test case we have in front of us. Even more, the OODA-loop is not really a loop. After executing a test case, the tester will not go through an OODA-loop to determine which test case is to be executed next. The next case has been prepared already, it’s simply the next one on the stack.
Why this test case
Each test case exists for a reason. It was created because the test strategy determined a certain test design technique needed to be applied on the test basis. Or put differently, if we think of strategy/tactics/operations (see illustration), it’s the test strategy that describes the strategic level of our testing. The tactical level, however, which connects the test strategy with the actual testing, isn’t described explicitly anywhere. It’s hidden in our choice of test design techniques. The test operations, finally, are described in our test cases. This means that the reason of existence for a particular test case isn’t described or documented explicitly. We have to actively interpret the test case, the test design technique and the test strategy to reconstruct that reason. The big question here is how closely this reconstruction resembles the original reasoning.
What has been tested
The question of what has been tested, can be asked on several different levels. On the level of the test case this question can be answered fairly easily: a test case has been fully executed or not, it passed or it failed. Answering this question on a higher level immediately becomes much more difficult. As just mentioned, the test tactics are not described explicitly. To get to the strategy we will have to make that leap ourselves. That leap as such can be made, but it prevents us from talking about the test strategy on a different level than either the details of the test cases or the abstraction of the test strategy. There is nothing in between.
A possible solution is to use a test coverage matrix. However, it’s a limited solution. In the end this matrix does nothing more than link the expectations from the test cases to the expectations from the test basis. Although that does give us another angle, it does not bring our thinking to another level.
So the gain is limited. So both of these approaches (linking test cases to either test strategy or to test basis) bring along their own share of problems. Perhaps that’s why there is a third and easier solution: having faith in the work that has been done earlier.
Where is the understanding?
If we now take a step back to get a good overview, one thing that stands out is the dispersedness of information. Information is less available, not as easily accessible, as we would want it to be. (See my earlier post on information debt for some more thoughts on this.)
Not only that, the understanding of what and how we are testing, is equally dispersed. Strategy and operations are separated by the implicit tactics of test design techniques. In the test operations the middle part of the OODA-loop, orientation and decision, have been separated from the other two elements, observation and action. The first two are part of test design; the latter two of test execution. And in fact the observation is strongly directed by test design. So only the action as such (marking the test case as passed or failed) happens completely inside the test execution activities.
All in all this reminds me strongly of the Chinese room, a thought experiment by John Searle. A man is sitting in a room and he receives pieces of paper with Chinese characters on them. He has a big book with rules about what Chinese characters he has to write in response, depending on the pieces of paper he receives. Now, in fact, the pieces he receives contain questions and the characters he writes down are the correct answers. To an outside observer it would look that the person inside the room knows Chinese, yet this is not the case. So the question is: where is the knowledge, the understanding of Chinese? It’s not in the man and it’s not in the book. A possible answer is that the understanding resides in the system as a whole, in the man together with the book.
A similar argument can be made about testing based on test cases. It’s impossible to point at one thing or person that understands the whole: from test strategy to tactics to planned and executed operations. This understanding is present however in the complete system consisting of test strategy, test design techniques, test coverage matrix, test cases, test results and people. If this is a problem or not will depend on how we evaluate the complexity of the information problem that is testing. With the ironic twist that the bigger we estimate the complexity, the more necessary but also the more difficult it will be to avoid this dispersedness of information - or at least limit it sufficiently.
This post was originally published on my old blog.